Why Ethereum Should Prioritize Bandwidth Over Latency: PeerDAS, ZK, and the Layering Tradeoffs
Published at 2026-01-08 13:54:04
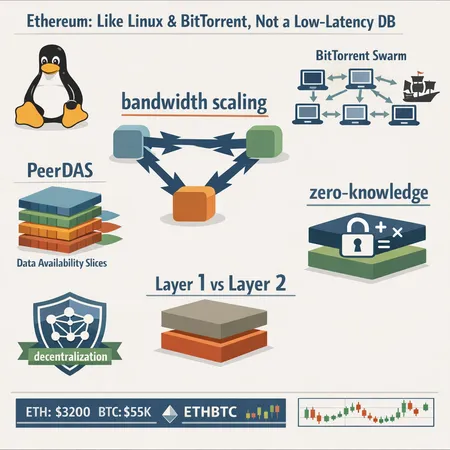
Summary
Vitalik’s recent analogy casting Ethereum more like Linux/BitTorrent than a low‑latency database shifts the engineering priority toward bandwidth and robust data availability rather than pure latency wins. PeerDAS (peer data availability sampling) and zero‑knowledge validity proofs are complementary primitives that reduce bandwidth costs for verifiers while preserving censorship resistance. That shift changes where transaction execution and UX should live: fast, UX‑friendly Layer 2s; a base layer optimized for secure settlement and data availability. For engineers and product leads, the consequences touch smart contract UX tradeoffs, node indexing requirements, and how markets read ETHBTC as a gauge of base‑layer confidence.
content":"## Why Vitalik’s Linux / BitTorrent Analogy Matters\n\nVitalik Buterin recently framed Ethereum less as a low‑latency database and more as an open, resilient infrastructure—think Linux and BitTorrent—where *data availability* and composability matter more than immediate per‑transaction latency. Reporters picked up the comparison as ETHBTC flirted with structural tests, and the metaphor helps reframe the core engineering tradeoffs for Layer 1. See coverage of this framing in Coinpaper and a deeper writeup of Vitalik’s point about speed limits in Cryptonews and Cryptonomist.\n\nThat framing is not academic posturing: it signals a roadmap. If Ethereum’s base layer becomes the reliable, highly available fabric for other systems (L2s, rollups, indexing layers), the ecosystem benefits by isolating trust assumptions and pushing costly low‑latency work off‑chain. In short: *optimize bandwidth and data availability on L1; let L2s optimize latency and UX.*\n\n## Bandwidth vs. Latency — What Engineers Should Care About\n\nLatency is about how quickly a single user sees a final result. Bandwidth is about how much data the network can reliably propagate and store. For a decentralized settlement layer, these are distinct constraints with different implications:\n\n- Latency wins: better for instant UX, micropayments, and interactive dApps. But low latency often requires stronger trust or heavier replication to avoid forks under load.\n- Bandwidth wins: more nodes can participate cheaply, data availability is robust, and clients can *probabilistically* verify the chain without re‑executing everything.\n\nVitalik’s point — also discussed in depth in Cryptonews — is that *Ethereum’s comparative advantage is not lowest latency per se but maximal, permissionless composability and long‑term resilience.* If L1 provides cheap, ubiquitous data availability, many different L2 designs (optimistic, zk, plasma variants, state channels) can coexist to give users near‑instant UX without sacrificing decentralization.\n\n## PeerDAS: Peer Data Availability Sampling Explained\n\nPeerDAS (peer data availability sampling) is a practical, probabilistic mechanism to ensure a block’s data is actually available to the network without every node downloading every byte. The high‑level flow:\n\n1. Block proposers erasure‑code (e.g., Reed‑Solomon style) the block into many small chunks and disseminate them across peers.\n2. Full and light nodes *sample* random chunks from random peers. If a sufficiently large, random sample is retrievable, the node can be confident the whole block is available with overwhelming probability.\n\nWhy this matters: the cost of full deterministic availability (downloading and storing every block) grows unbounded with throughput. Sampling converts that linear verification cost into a small, constant expected bandwidth cost per verifier while preserving strong soundness guarantees.\n\nTechnical notes and tradeoffs:\n\n- Erasure coding increases redundancy so missing chunks can be reconstructed if a small fraction are withheld.\n- Sampling probability needs to scale with threat models (e.g., proportion of Byzantine peers) and expected throughput.\n\nPeerDAS is the *data availability* half of the picture. It pairs naturally with fraud proofs or succinct validity proofs to handle incorrect or withheld data. Without PeerDAS‑style techniques, raising on‑chain throughput quickly makes full‑node participation infeasible for honest validators and endangers decentralization.\n\n## Zero‑Knowledge Proofs: Validity, Succinctness, and Bandwidth Savings\n\nZero‑knowledge (ZK) proof systems tackle a complementary axis: they make correctness verification much cheaper. Instead of re‑executing a large batch of transactions, a verifier checks a small, succinct proof that the state transition was valid. The verifier cost becomes tiny and non‑interactive, which is a huge win for bootstrapping and light clients.\n\nHow ZK and bandwidth interact:\n\n- ZK *validity proofs* compress verification time and CPU work for verifiers, but they do not necessarily replace the need for data availability unless you adopt a fully zk‑enabled model where posted proofs contain everything needed for reconstruction.\n- If a rollup posts only a proof and no data, the network still needs a way to reconstruct or trust the state—hence the need for sound DA layers or proof‑of‑publication designs.\n\nVitalik has been explicit that Ethereum cannot simply compete on raw speed alone; instead it should emphasize bandwidth, reliability, and composable proofs that let many execution environments interoperate. Cryptonews captures the nuance: ZK is powerful, but proving costs, prover infrastructure, and developer ergonomics are real constraints.\n\n## Layer 1 vs Layer 2: Where Each Responsibility Should Live\n\nAdopting the Linux/BitTorrent model steers responsibilities:\n\n- Layer 1 (the base): become the *settlement and data availability layer*. Prioritize censorship resistance, open participation, and efficient DA mechanisms (PeerDAS, erasure coding). Keep the core protocol narrowly focused so node requirements remain reasonable.\n\n- Layer 2 (rollups, sequencers, channels): handle execution, latency, and rich UX. L2s can be specialized: zk‑rollups for high throughput and provable correctness, optimistic rollups for simpler prover models, state channels or payment networks for microsecond‑scale payments.\n\nThis separation yields practical benefits: L2 teams iterate quickly on UX and gas abstractions, while L1 upgrades focus on bandwidth guarantees, indexing primitives, and stateless client support. The result is more composability and clearer trust boundaries for enterprises and auditors.\n\n## Developer Tooling, Indexing, and Node Requirements\n\nIf L1 emphasizes bandwidth and DA, tooling and infra must evolve accordingly:\n\n- Indexers and event tracing will remain largely off‑chain or run by specialized services. Enterprises will expect stable, queryable APIs and SLAs for historical data rather than relying on every node to do heavy indexing. This is where Bitlet.app and other middleware providers become crucial for product teams.\n\n- Node requirements shift: full nodes should be optimized for high‑throughput data handling and enabling sampling rather than bloated archival storage. Stateless client work reduces state bloat on validators and makes participation less resource‑intensive.\n\n- Developer tooling for zk workflows: provers, circuit libraries, and integrated devtools will be essential. Building/debugging circuits has a steeper curve than EVM bytecode, so improved abstractions (higher‑level DSLs, prebuilt circuits) will accelerate adoption.\n\nPractical change: teams will increasingly treat on‑chain state as canonical but query off‑chain indexes for UX, analytics, and reporting. That reduces the need for every enterprise node to be a full archival node, cutting costs while keeping verifiability intact.\n\n## Smart Contract UX Tradeoffs and Practical Consequences\n\nDesigners must trade: immediate perceived finality versus provable, robust settlement. Common patterns:\n\n- UX via L2: Offer instant confirmations on L2 with a clear, auditable exit path on L1. Users get low latency; auditors get L1 assurances.\n\n- Data‑heavy contracts on L1: If a contract needs to publish large datasets (oracles, on‑chain orderbooks), expect higher gas costs and plan for DA primitives (e.g., chunked posting with commitments and proofs).\n\n- Indexing and UX: Apps relying on fine‑grained event histories should use dedicated indexers or rely on sequencer logs with cryptographic anchoring back to L1 for dispute resolution.\n\nFrom an engineering perspective, these tradeoffs are deliberate: you accept slightly higher friction to post big data on L1 in exchange for lower long‑term verification costs across the network.\n\n## Indexing, Bootstrapping, and Enterprise Adoption\n\nEnterprises care about predictable SLAs, auditability, and low operational cost. A bandwidth‑first L1 affects them as follows:\n\n- Bootstrapping new nodes becomes cheaper if data availability sampling and succinct proofs reduce storage and computation needs.\n- Audits and compliance are easier when proofs and DA commitments provide deterministic evidence of state transitions.\n- However, enterprises will demand robust off‑chain tooling: managed indexers, replayable event logs, and monitoring services.\n\nThe upshot: enterprises will pivot toward hybrid models—on‑chain settlement with off‑chain analytics—rather than trying to run fully independent archival stacks for every deployment.\n\n## ETHBTC as a Sentiment Signal for Base‑Layer Confidence\n\nMarket dynamics between ETH and BTC often reflect whether traders view Ethereum as a resilient base layer or a risky, upgrade‑dependent experiment. When ETHBTC compresses (ETH loses value vs BTC), traders may be signaling uncertainty about Ethereum’s ability to scale securely at base layer. Coinpaper covered how ETHBTC at ~0.035 sparked commentary as Vitalik framed Ethereum as a Linux/BitTorrent style system: improving DA and bandwidth posture is partly a credibility play.\n\nIn practice, credible progress on DA primitives (PeerDAS‑style sampling, better erasure coding, modular DA layers) and healthier ZK tooling should improve perception of Ethereum as a durable settlement layer. Market participants reward systems that can prove they can scale bandwidth without losing decentralization — that’s the core of the Linux/Bittorrent metaphor.\n\nFor many traders, [Bitcoin](/en/blog/Bitcoin) remains a primary bellwether; watching ETHBTC is watching the market’s confidence in Ethereum’s base‑layer robustness.\n\n## Recommendations for Engineers and Product Leads\n\n- Design for modularity: treat L1 as DA + settlement and route UX to L2s.\n- Implement sampling‑friendly nodes and support erasure coded block production if you run infrastructure.\n\n- Invest in ZK tooling where proofs reduce long‑term verifier costs. Prioritize developer ergonomics around proving (prebuilt circuits, standardized proving infra).\n\n- Build or rely on managed indexing and analytics for enterprise apps. Don’t assume every client will run an archival node.\n\n- Monitor ETHBTC and community signals: base‑layer credibility matters for adoption and institutional confidence.\n\n## Closing Thought\n\nVitalik’s analogy is useful because it changes the optimization objective: maximize reliable, permissionless data availability first, and let specialized layers deliver the fast, delightful UX users expect. For intermediate engineers and product leads, that means shifting architecture and tooling decisions now — embrace PeerDAS concepts, build with ZK‑friendly assumptions, and decouple UX from base‑layer guarantees. The result is a more scalable, composable, and enterprise‑friendly Ethereum ecosystem.\n\n## Sources\n\n- [ETH/BTC coverage and Vitalik’s Linux/BitTorrent analogy (Coinpaper)](https://coinpaper.com/13612/ethbtc-at-0-035-vitalik-compares-ethereum-to-linux-as-breakout-test-looms?utm_source=snapi)\n- [Vitalik on why Ethereum can’t compete on speed alone (Cryptonews)](https://cryptonews.com/news/vitalik-buterin-explains-why-ethereum-cant-compete-on-speed-alone/)\n- [Vitalik’s public framing via BitTorrent/Linux models (Cryptonomist)](https://en.cryptonomist.ch/2026/01/08/ethereum-layer1-bittorrent-linux-models/)",
Share on:


