Base’s Shift from OP Stack to a Unified Stack: What Developers, DevOps, and Risk Teams Must Do
Summary
Executive overview
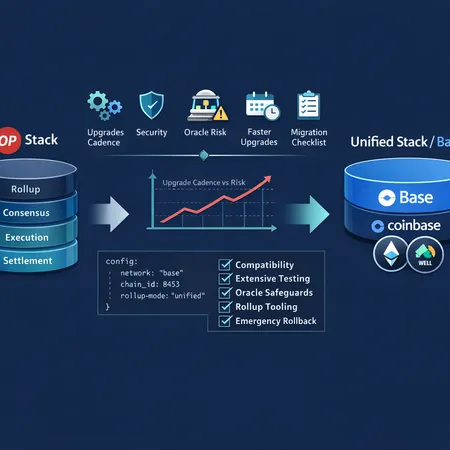
Base — the Coinbase-backed Layer‑2 that helped bring mainstream developer activity to Ethereum rollups — is switching from an OP Stack-based architecture to a single unified stack. The change is billed as a way to speed upgrades and reduce divergence between Base-specific features and the upstream OP Stack codebase. For engineers, operators, and risk officers, this matters: faster upgrades can mean quicker security patches, but a new stack brings compatibility changes, different tooling expectations, and migration risk for live DeFi contracts.
Developers building on Base should treat this as a platform-level migration window: plan tests, revalidate assumptions about the node software and RPC behavior, and strengthen oracle posture. This article synthesizes the technical rationale for the move, explains likely effects on upgrade cadence and security, covers implications for OP Stack tooling and rollup architectures, and translates the lessons from recent oracle-driven incidents into operational recommendations. We also provide a checklist you can run through before, during, and after migration.
Why Base is changing stacks now
Base’s leadership has argued the unified stack will let the network ship upgrades more quickly and maintain a common codebase tailored to its operational needs. The public announcement framed the decision around two core drivers: faster upgrade cadence and simplified maintenance of Base-specific features. See the official coverage of the shift for the original phrasing and rationale.
Operationally, the OP Stack was designed as a modular, widely adopted rollup framework. But when a rollup diverges from the upstream stack — adding custom runtimes, sequencer features, or node extensions — it often creates a maintenance burden: merges, rebases, and backports accumulate. A unified stack reduces that churn by consolidating Base’s production requirements into a single, opinionated codebase that the Base team controls directly source.
From a Coinbase-backed governance and trust perspective, timing also aligns with Base’s push to accelerate feature velocity: tooling improvements, fraud-proof optimizations, and security hardening that would be cumbersome under the previous model.
Expected benefits: upgrades, security, and developer ergonomics
The unified stack aims to deliver several advantages:
- Faster and more predictable upgrade cadence: fewer external merge dependencies means Base can ship hotfixes and feature releases without waiting for upstream forks or complex backports.
- Reduced divergence and clearer release management: teams will be able to reason about a single code path that implements Base semantics.
- Potentially improved security posture: a tighter codebase lowers the surface for integration mistakes, and a central team can standardize auditing, test coverage, and CI/CD for all production releases.
- Better platform-level observability and ops defaults: opinionated defaults can make it easier to deploy standardized nodes, monitoring, and backups across validators and sequencers.
For many DevOps teams, these changes will be welcome because they reduce the long-term maintenance burden. Faster patching windows mean vulnerabilities can be remedied quickly, which is particularly relevant for DeFi primitives where small bugs escalate fast.
Migration risks for dApp developers and operators
A new stack is not purely positive: it carries short- and medium-term risks practitioners must plan for.
- Compatibility drift with OP Stack tooling: some developer tools, local testing frameworks, or node plugins that assumed OP Stack internals may require updates or rewiring. Expect changes to node flags, RPC endpoints, tracing semantics, state export formats, and gas estimation heuristics.
- Differences in rollup semantics: subtle differences in how the stack handles sequencing, batch submission, or reorg resolution may alter front-running profiles and block-atomic invariants.
- Versioning and client upgrades: validators and sequencer operators must coordinate upgrades to avoid temporary chain splits or RPC inconsistencies. Testnets and staging environments must mirror upgrade plans.
- Integration tests that depend on exact client behavior (e.g., mempool ordering or tx propagation) may fail and require retuning.
- Third-party dependency lag: wallets, relayers, indexers, analytics providers, and bridges will need to adapt; while many will move quickly, there will be a period where some services lag behind.
Mitigation is straightforward in principle: maintain pinned versions for production, run a parallel staging environment on the new stack early, and allocate time for upstream tooling teams to release compatibility patches.
Compatibility implications for OP Stack tooling and rollup architectures
The OP Stack is an ecosystem: tooling like local dev environments, fraud-proof tools, sequencer logic, and telemetry were built with OP Stack conventions in mind. A unified stack that re-implements those conventions can be orthogonal or backward-compatible, but in practice:
- Some OP Stack SDKs may remain compatible if the unified stack preserves public RPC and message formats. However, private/internal APIs and build pipelines will likely diverge.
- Rollup architectures that depend on specific OP Stack-internal behaviors (for instance, optimized fraud-proof submission flows or specific batch formats) should prepare for revalidation. Expect some rewriting of integration layers.
- Bridges and cross-rollup relayers must be tested end-to-end; differences in canonical transaction receipts, logs, and proof formats can break indexing and finality assumptions.
In short, plan for a non-zero porting cost. If your stack uses OP Stack internals directly (vs. only standard Ethereum JSON-RPC), audit those touchpoints first.
How recent incidents on Base change the calculus for risk teams
Operational incidents on Base have highlighted how protocol-level faults and oracle errors can cascade into mass liquidations and borrower losses. A recent example involved oracle-driven liquidations affecting cbETH exposure and the Moonwell protocol, prompting Moonwell to propose a recovery plan after losses to borrowers on Base. That case study is a sharp reminder: faster upgrades help, but they do not eliminate systemic oracle risk — and they introduce new vectors that risk teams must consider in their migration plans (read the incident breakdown here).
Two immediate lessons for risk officers:
- Upgrades are a double-edged sword for oracles. Quicker patching means you can fix price-feed bugs or add safeties faster. But if an upgrade changes block timing, ordering, or gas characteristics, it can also affect how oracle relayers and aggregators report prices (latency and sequencing matter).
- Oracle design needs to be robust to client quirks. Given the possibility of RPC subtlety during the migration, protocols should prefer designs that reduce reliance on single-node feeds and incorporate on-chain fallbacks (TWAPs, bounded slippage checks, and multi-provider consensus).
For a concrete incident reference and recovery plan context, see the Moonwell case study on Base and the cbETH liquidation fallout in the reporting by Blockonomi.
Practical mitigations: how to harden oracles and risk systems
Make these operational changes now:
- Use multiple independent oracle providers and require quorum thresholds for critical price updates.
- Implement on-chain aggregation with fallback windows: if an external feed fails or reports extreme moves, fall back to a TWAP or a vetted backup feed before triggering liquidations.
- Add conservative liquidation parameters and larger safety margins during and immediately after scheduled Base upgrades.
- Deploy automated anomaly detection on price feeds and on-chain behavior (sudden volume/price divergence, oracle staleness, abnormal gas spikes).
- Maintain post-mortem-ready scripts and clear governance-execution pathways (timelock/guardian flows) to pause risky actions in extreme events.
These controls are relevant regardless of stack, but they are especially important during a base-layer migration window where unexpected behavior is more likely.
Migration checklist for teams deploying or hardening apps on Base
The following checklist is split into phases. Treat it as a practical playbook for engineers, DevOps, and risk officers.
Preparation (4–8 weeks before upgrade)
- Inventory: map all contracts, indexers, relayers, wallets, and off-chain services that interact with Base.
- Pin and document current node versions and dependencies; identify where OP Stack internals are referenced.
- Align with Base upgrade timeline and subscribe to official announcements.
- Create a staging environment that mirrors the planned unified stack release.
- Run fuzz and integration tests against the staging chain; pay special attention to RPC edge cases and mempool behavior.
Developer & integration work (2–4 weeks before)
- Re-run full integration test suites; fix failing tests and update any components that relied on OP Stack internals.
- Validate gas estimation and nonce management under the new stack.
- Verify log formats, event ordering, and receipt fields consumed by indexers.
- Update SDKs, clients, and CI to support new node flags or endpoints.
Oracle & risk controls (1–2 weeks before)
- Enforce multi-provider oracle configurations and quorum rules.
- Configure TWAP windows, stale-feed detection, and on-chain guard rails.
- Increase collateralization or widen liquidation thresholds for sensitive positions (e.g., cbETH exposure) prior to the upgrade.
Deployment & upgrade window
- Coordinate a timeboxed rollout with validator/sequencer operators and third-party infrastructure teams.
- Keep a hot rollback plan: pinned snapshot, clear upgrade-failure steps, and contact lists.
- Monitor health metrics: RPC latency, head reorgs, mempool depth, and oracle update cadence.
- Be prepared to pause risky flows (borrowing, liquidation executors) if anomalies appear.
Post-upgrade validation (0–72 hours after)
- Re-run end-to-end sanity checks: oracle updates, borrowing/lending flows, settlement paths, and indexer sync.
- Validate user-facing components and relayer latency under production load.
- Collect telemetry and run a short post-mortem drill for any anomalies.
Operational recommendations for long-term resilience
- Treat the unified stack as a platform dependency; maintain a small cross-functional team responsible for stack upgrades, CI, and drift detection.
- Standardize on robust hedging and insurance approaches for under-collateralized exposures.
- Keep up-to-date with Base release notes and coordinate with ecosystem tooling providers early — breaking changes are survivable when announced and rehearsed.
For teams that expose payment rails or user products, consider testing with wallets and services such as Bitlet.app to ensure UX continuity across the migration.
Final thoughts
Base’s migration to a unified stack is an operationally sensible move that should yield faster upgrades and a tighter security posture in the medium term. But faster platform velocity raises short-term compatibility and risk-management requirements. The Moonwell/cbETH incident is a concrete reminder: protocol incidents driven by oracle failures can cascade quickly, and a stack migration amplifies the need for robust oracle design, testing, and emergency controls.
The practical path forward is clear: inventory your dependencies, run staging tests early, harden oracle and liquidation logic, and coordinate closely with Base and third-party infrastructure teams. Treat the migration as an opportunity to simplify assumptions and reduce technical debt — but do it methodically.