Flow Exploit and the Rollback Controversy: Lessons in Governance and Crisis Response
Summary
Executive overview
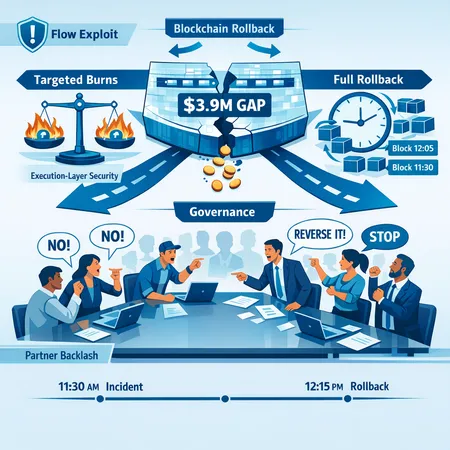
In early April 2025 the Flow blockchain (ticker: FLOW) was hit by an execution-layer exploit that allowed an attacker to extract approximately $3.9M in assets. The core team paused the network and floated a proposal for a full chain rollback — a blunt instrument that would have rewound the ledger to a pre-exploit state. That proposal ignited strong backlash from ecosystem partners who said they were not consulted and warned a rollback would damage downstream systems and user trust. Flow ultimately abandoned a full rollback in favor of targeted token burns and coordinated remediation. This incident is a useful case study for application-layer chains wrestling with immutability, restitution, and governance under stress.
What happened: timeline of the $3.9M exploit
Discovery & halt (Day 0–1): On discovery of anomalous transfers originating at the execution layer, Flow’s operators paused block production to stop further damage and begin a forensic assessment. The pause was framed as a short-term safety measure.
Assessment & rollback proposal (Day 2–3): Early forensic signals suggested the exploit occurred at the execution layer and affected specific contract flows and token balances. Flow engineers drafted a proposal to rewind the chain state to a block just before the exploit — a full rollback intended to restore stolen funds by erasing the illicit transactions from the canonical ledger.
Partner backlash (Day 3–5): Several ecosystem partners — wallets, marketplaces, validators and third-party services — pushed back, saying they had not been properly consulted and warning that a rollback would break integrations, invalidate off-chain state and create legal/operational chaos. Coverage capturing partner reactions noted many felt blindsided by the rollback suggestion and demanded more collective decision-making reported coverage summarized below.
Pivot to targeted remediation (Day 6–10): After public pushback and internal debate, Flow abandoned the full rollback idea and moved to a remediation approach focused on targeted token burns for the attacker-controlled assets and other surgical measures. The public rationale was to limit collateral damage while still attempting to make victims whole where possible. The team communicated the decision and began implementing burns and coordination with affected projects coverage and reporting of this pivot is available here.
Post-incident: forensic reports, audits, and community debriefs followed. The incident triggered renewed conversations about governance thresholds, emergency powers, observability at the execution layer, and crisis playbooks for application chains.
Technical anatomy: what an "execution-layer" exploit means in practice
An execution-layer exploit is one that targets how transactions are processed and applied to the ledger state rather than, for example, a consensus-layer bug. In Flow’s case the attack led to unauthorized moves or manipulations of token balances and contract state across multiple contracts. The precise vulnerability vectors vary by incident — common paths include logic errors in contract libraries, unchecked minting functions, or flaws in how cross-contract calls are sequenced and validated.
Two important technical features that aggravate execution-layer incidents:
State complexity: Application-layer chains like Flow run many rich contract systems that maintain interdependent state. A single bad state transition can cascade in complicated ways.
Observability limits: Rapidly distinguishing legitimate complex activity from exploit-driven state changes is non-trivial. Forensic timelines often lag the live impact.
The Flow team’s initial halt and rollback thinking reflected the desire to quickly stop damage and revert state to a known-good checkpoint. But execution-layer issues also mean that rolling back a ledger can undo legitimate, complex sequences that downstream services already reflected off-chain.
Remediation options: rollback vs targeted burns — trade-offs explained
When a large exploit occurs projects typically consider at least two remediation models: a full ledger rollback or surgical remediation (targeted burns, selective restores, or compensations). Each has trade-offs.
Full rollback:
- Pros: Can fully restore stolen assets to pre-exploit holders in a single atomic action; conceptually simple restitution for victims.
- Cons: Breaks ledger immutability, undermines the “this time it’s on-chain and final” promise; can invalidate off-chain contracts and external systems; places enormous discretionary power in the hands of a small operator group; legal/regulatory exposure for undoing finality.
Targeted burns / surgical remediation:
- Pros: Preserves canonical history and immutability; limits changes to known malicious balances or contracts; better respects the expectation that the chain is final.
- Cons: Requires accurate identification of attacker-controlled assets and low false-positive risk; may not fully compensate victims; needs strong cross-project coordination to enact burns without causing collateral damage.
In Flow’s case, the community weighed these trade-offs and — after partner outcry — opted for targeted burns and coordinated remediation rather than a full rollback. Reports describe the team choosing to prioritize ledger integrity while seeking pathways to restitute where traceable and technically possible coverage here.
Partner backlash: why ecosystem actors pushed back
Several recurring themes explain partner anger and public criticism:
Lack of consultation: Partners reported they were not adequately consulted before the rollback proposal was floated publicly. When downstream services learn about existential changes via public channels, trust erodes quickly.
Operational fragility: A rollback could invalidate off-chain reference data, transaction-receipt mappings, marketplace listings, and other integrations. For many service operators, the risk of cascading failures outweighed the benefit of a clean ledger reset.
Legal & custodial concerns: Custodians, exchanges and regulated entities worried about legal exposure if they were forced to reverse customer balances that had already been treated as final.
Reputation and governance legitimacy: A rollback decision made unilaterally or without clear governance signals looks centralized. Partners feared precedents that placed too much emergency power in the core team.
Coverage at the time captured the sense that ecosystem participants felt blindsided and sought clearer consultative governance mechanisms in the future (see reporting on partner reactions and the notion of being blindsided) source.
Governance lessons: what other application-layer chains should learn
This incident exposes repeated governance themes that chains should address proactively.
Pre-agreed emergency playbooks: Define, before any incident, the set of allowable emergency actions (pauses, time-limited forks, rollbacks), decision thresholds, and who is consulted. Ambiguity breeds conflict.
Multi-stakeholder consultation channels: Emergency committees should include validators, major dapp operators, legal advisors and user representatives. Make these groups operational (contactable 24/7) and empowered to advise rapidly.
Transparent escalation paths: If a rollback is considered, publish a clear rationale, the timeline, and a structured consultation process. Even when speed is essential, structured transparency reduces the appearance of secrecy.
Technical safeguards and observability: Invest in richer execution-layer monitoring, replay tools, and real-time forensic capabilities so you can prove with evidence which balances are malicious and which are legitimate.
Pre-funded restitution mechanisms: Consider on-chain insurance pools, socialized treasury funds, or bonded compensation schemes that can compensate victims without undermining immutability.
Governance limits and timelocks: Emergency powers should be time-limited and subject to post-facto governance votes where feasible. This balances the need for quick action with long-term legitimacy.
Simulation & tabletop exercises: Regular drills with partners (validators, wallets, marketplaces) simulate incidents and enforce well-practiced coordination procedures.
A recommended crisis playbook for protocol operators
Below is a concise, operational playbook operators can adopt and adapt.
Detection & containment
- Immediately isolate the attack vector and, if necessary, pause the relevant protocol subsystem. Communicate a brief initial status to the community.
Forensic triage (hours 0–48)
- Run live forensic captures and fast-track replay tools to scope the damage.
- Produce an early incident report with observable artifacts.
Convene emergency committee (within 24 hours)
- Pull together validators, affected projects, legal counsel, and an independent security third party.
Evaluate remediation options (48–72 hours)
- Assess feasibility of full rollback vs targeted measures using forensic evidence. Price collateral damage: off-chain integrations, legal risk, UX impacts.
Public consultation & decision (as fast as practicable)
- Share the evidence and proposed path with stakeholders via pre-established channels. If a rollback is being proposed, publish the technical block-range, expected side effects, and a rollback test plan.
Execute with safeguards
- If remediating via burns/compensations, maintain rigorous evidence trails for each action and give affected parties time-limited windows to object.
Reconciliation & audit (post-mitigation)
- Commission an independent audit and publish a comprehensive post-mortem with remediation steps and timelines.
Update governance & tooling
- Codify learnings into governance rules, improve observability, and consider financial protections like insurance or a restitution fund.
Technical hardening recommendations
- Harden minting and privileged functions with multi-sig and timelocks.
- Increase execution-layer monitoring and anomaly detection tuned to business logic flows.
- Maintain snapshot & replay infrastructure that can test rollback scenarios in a sandbox without touching the live ledger.
- Encourage minimal-trust integration patterns for third-party services to reduce coupling vulnerability.
Final reflections
The Flow incident underscores a perennial tension in blockchain design: the allure of on-chain finality and immutability versus the human imperative to restore victims after malicious theft. There is no one-size-fits-all answer. For many ecosystems, preparedness, transparency, and multi-stakeholder governance make the difference between a bruising one-off and long-term reputational damage. Application-layer chains should take this moment to codify emergency rules, run drills with partners, and improve forensic tooling so that future incidents can be resolved quickly and with legitimacy.
For protocol operators and governance participants reading this: use the Flow episode as a blueprint for building durable incident-response practices that respect both technical realities and the social fabric of your ecosystem. Platforms that mix custody, marketplace activity, and complex off-chain integrations — including services like Bitlet.app — will be particularly sensitive to how these choices are communicated and executed.