Render Network’s Dispersed: Can Decentralized GPU Markets Unclog Cloud Bottlenecks for AI?
Summary
Executive snapshot
Render Network’s new Dispersed product is a purpose-built marketplace for distributed GPU compute that promises to tap idle GPU capacity — from workstations, edge devices and underused datacenter racks — to run AI workloads. The pitch is straightforward: relieve centralized cloud bottlenecks by pooling existing compute, orchestrating jobs across heterogeneous hardware, and using tokenized incentives (RENDER) to unlock supply. This piece breaks down what Dispersed offers, the infrastructure problems it targets, Render’s technical approach, the economics of incentivizing idle GPUs, and whether a decentralized GPU market can realistically compete with AWS, Google Cloud, and Azure.
What Dispersed offers
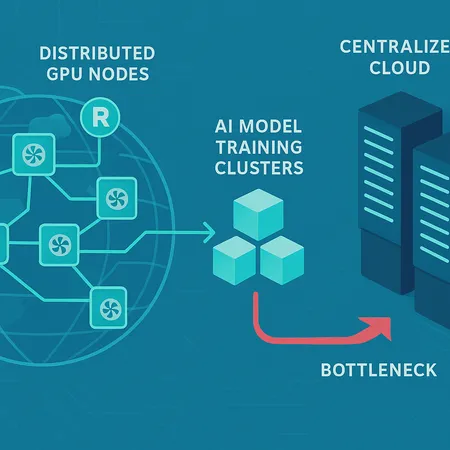
Dispersed is positioned as a distributed GPU platform that connects demand for GPU cycles with a varied supply of unused GPU capacity. According to the official announcement, the system focuses on: efficient task distribution, GPU virtualization layers, secure data handling, and a marketplace model where suppliers and consumers interact under programmatic terms. The goal is to provide both a consumer‑facing API for submitting workloads and a node client for suppliers to join the network and catalogue available resources.
Importantly, Dispersed is designed with AI workloads in mind — not just generic batch compute. That means optimizations for model training and inference patterns, such as batching, checkpointing, and tolerance for preemption. The announcement frames Dispersed as a way to reduce cloud dependence while offering a path to monetize idle GPU assets. For a deeper read on the product launch see the announcement coverage here: Render Network Targets Cloud Bottlenecks With Distributed GPU Platform.
The centralized GPU bottleneck problem
Cloud providers and hyperscalers have been the default solution for scalable GPU compute, but the model shows stress points. Demand for AI chips has surged — driven by large model training, generative AI inference, and enterprise AI pilots — and industry analysis highlights how this has tightened supply chains and driven price pressure on GPU instances. The underlying trend — massive demand concentrated on a relatively small set of GPU vendors and datacenters — creates pricing volatility, long lead times for capacity, and vendor lock‑in for heavy users. For context on how pivotal GPU supply (and Nvidia specifically) has become to the AI economy, see this analysis of chip demand and vendor positioning: Better Buy in 2026: Nvidia or Bitcoin?.
These bottlenecks manifest as: spot shortages for training clusters, unpredictable hourly costs for GPU instances, throttled experimentation for startups, and geographic concentration that increases latency for certain users. Centralized clouds are also optimized for uptime and predictable performance, which is vital — but those guarantees come at a premium that not every workload needs.
Render’s technical approach to distributed GPU compute
At a technical level, a decentralized GPU market must solve three core challenges: orchestration, data movement, and security/reliability.
Orchestration and heterogeneity
Dispersed proposes an orchestration layer that abstracts hardware differences and exposes a unified task API. This layer schedules jobs across nodes based on capability (memory, compute), availability windows, and pricing. To handle heterogeneity, the platform needs containerized runtimes, driver compatibility layers, and runtime negotiation so an owner’s consumer GPU can execute parts of a model pipeline.
This model works best when tasks can be partitioned: distributed training with model parallelism, sharded datasets, or batched inference. For large‑scale synchronous training that demands identical GPUs and ultra‑low latency interconnects (e.g., NVLink clusters), a patchwork of consumer GPUs will struggle to match specialized cloud instances. But for asynchronous workflows, hyperparameter sweeps, batch pretraining, and inference farms, a distributed approach can be effective.
Data locality and transfer
GPU compute is only as useful as the data fed into it. Dispersed must therefore balance data transfer costs and latency with compute placement. Strategies include: caching frequently used datasets at edge nodes, integrating object stores with proximity scoring, and allowing users to specify data‑sensitivity rules (keep data in region X). For federated or privacy‑sensitive workloads, the system can employ encrypted computation or bring small models to data rather than move raw datasets.
Security, sandboxing and SLAs
Running third‑party code on consumer or mixed datacenter GPUs raises attack surface and reliability concerns. Trusted execution environments, sandboxing (e.g., container isolation), and robust attestation are needed to meet enterprise minimums. SLAs in a decentralized marketplace will likely be probabilistic rather than the hard 99.99% uptime cloud buyers expect. Render’s architecture must therefore include redundancy, checkpointing and preemption policies that reduce job failure impact.
Incentives and token economics: how RENDER could supply idle GPUs
One of Dispersed’s core differentiators is token‑based incentives. The RENDER token can serve several functions: remunerating suppliers, staking for reputation, and providing micropayments that lower friction for short‑lived jobs.
A practical token model could combine: per‑minute payouts to suppliers based on GPU specs and job characteristics; bonding/staking to qualify nodes for higher‑value workloads; and dynamic pricing markets where spot demand sets token rates. Tokenization reduces payment settlement friction and enables sub‑minute billing — attractive for bursty inference workloads.
However, tokens do not magically create GPU supply. Suppliers will evaluate: expected payout vs. electricity and wear costs, administrative overhead to join the network, and privacy/security risk. For many suppliers (e.g., organizations with spare datacenter racks) the key incentive is predictable revenue with minimal operational hassle; speculative token upside helps, but is unlikely to be the primary driver for enterprise capacity providers.
To scale, token economics must be paired with: simple onboarding, clear SLAs, low payment latency, and mechanisms to signal quality (reputation, stake). Without those, supply will stay fragmented and price volatility will deter long‑term buyers.
Business models and go‑to‑market paths
Render and other decentralized GPU projects typically pursue a tiered approach:
- Focus first on workloads where centralized clouds are overkill or overpriced — batch training, non mission‑critical inference, hyperparameter sweeps, and development/test runs. These are the low hanging fruit.
- Offer hybrid integration: pipelines can burst to Dispersed when cloud instances are fully allocated, enabling follow‑the‑workload elasticity.
- Build partnerships with colocations or GPU farms to add more enterprise‑grade capacity and reduce heterogeneity.
- Provide managed services (SaaS layer) that hide marketplace complexity from buyers.
Enterprise buyers are unlikely to replace their primary cloud providers overnight. Instead, decentralized compute will earn space as a complement — cheaper spot compute for scale trials, overflow capacity during peaks, and specialized inference endpoints close to users. Mentioning real integrations and proof‑points will be crucial to winning trust; enterprises care about benchmarks and predictable TCO more than tokenized upside.
Can Dispersed scale to meaningfully compete with AWS/Google/Azure?
Short answer: not immediately, but there's a plausible competitive niche.
Large cloud providers compete on reliability, networking (e.g., NVLink), managed software, and integrated services. They also benefit from long‑term contracts, volume discounts, and global datacenter footprints. A decentralized marketplace faces three structural headwinds: hardware heterogeneity, reliability/SLAs, and enterprise trust.
That said, the supply problem these clouds face — particularly for GPUs and specialized AI hardware — creates a natural market opening. The Motley Fool piece on Nvidia and chip scarcity illustrates why alternate supply sources matter: demand is growing faster than centralized capacity can expand, and spot prices spike during cycles of interest. A distributed marketplace can absorb marginal demand, improve utilization of existing GPUs, and offer compelling price points for non‑latency‑sensitive workloads.
Realistically, Dispersed can scale in phases:
- Phase 1: Win cost‑sensitive, latency‑tolerant workloads (batch training, research experiments).
- Phase 2: Add enterprise suppliers and stronger SLAs to handle more critical workloads.
- Phase 3: Target inference edge markets and hybrid orchestration that transparently routes tasks between cloud and decentralized pools.
To reach parity for synchronous large‑model training will require either aggregation of homogeneous racks (partnering with colos) or new abstractions that make heterogeneity invisible to frameworks like PyTorch. Given the capital intensity of hyperscale datacenters, decentralization is unlikely to replace cloud giants, but it can and probably will become a durable alternative channel for a large subset of AI compute demand.
Practical checklist for product managers and AI infrastructure buyers
If you’re evaluating Dispersed (or similar decentralized GPU options), consider this checklist:
- Workload fit: Is your workload tolerant to preemption and modest interconnect latency?
- Data governance: Can you move or encrypt the datasets required, or must data remain in controlled regions?
- Cost predictability: Does the pricing model support budgeting (spot markets vs. committed usage)?
- Integration: How easily will the marketplace plug into MLOps pipelines and CI/CD?
- SLAs and reliability: Are there fallback paths (cloud burst) and clear recovery strategies?
- Security: What attestation, sandboxing, and provenance tools are in place to protect IP and data?
- Token risk: If payouts are denominated in RENDER or another token, what are the currency risk and conversion processes?
These pragmatic questions will determine whether Dispersed is a pilot project or a core piece of infrastructure in your stack.
Conclusion
Render Network’s Dispersed targets a real pain point: centralized GPU scarcity and the economic inefficiencies of idle hardware. Technically, the offering makes sense for many AI workloads that are flexible on latency and topology, and tokenized incentives can lower friction for micropayments and reputation systems. But to meaningfully threaten cloud incumbents, Dispersed must overcome heterogeneity, prove reliable SLAs, and build partnerships that supply homogeneous, enterprise‑grade capacity.
For blockchain product managers and AI infrastructure buyers, Dispersed is a strategic complement to existing clouds — worth piloting for batch training and inference use cases where cost and time‑to‑iterate matter more than absolute performance guarantees. As the market for AI chips tightens and demand remains elevated, decentralized GPU markets could become a critical layer of the compute stack rather than a niche curiosity. For teams exploring alternatives to hyperscaler lock‑in, Dispersed is now a practical option to test alongside cloud burst strategies and hybrid architectures. Bitlet.app’s users evaluating decentralized compute should watch how token economics and SLA maturity evolve before committing mission‑critical workloads.
Sources
- Render Network Targets Cloud Bottlenecks With Distributed GPU Platform: https://news.bitcoin.com/render-network-targets-cloud-bottlenecks-with-distributed-gpu-platform/
- Analysis of GPU demand and Nvidia’s role in AI chip markets: https://www.fool.com/investing/2025/12/14/better-buy-in-2026-nvidia-stock-or-bitcoin/
For broader industry context, readers may also find discussions around DeFi and macro crypto trends like Bitcoin useful when considering tokenized incentive design and market psychology.
