Subnet 3
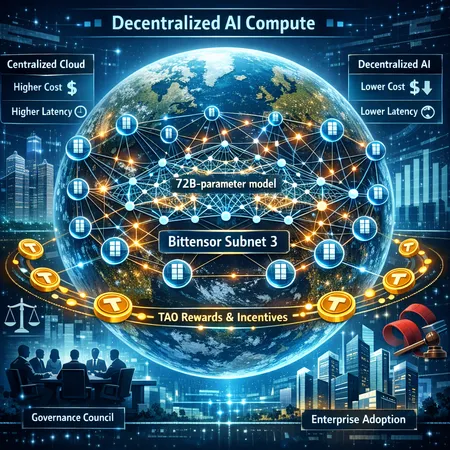
What Bittensor’s Subnet 3 and a 72B Model Mean for Decentralized AI Compute
Bittensor’s Subnet 3 training a 72B-parameter model across 70+ nodes is a watershed for decentralized AI compute — showing technical feasibility while exposing economic, governance, and operational trade-offs. This article breaks down the architecture, TAO token incentives, enterprise prospects, and the hurdles that will determine whether decentralized training becomes a real competitive layer to centralized labs.
Published at 2026-03-14 16:16:26
No tags to show yet.